
RAG
什么是检索增强的生成模型(RAG)
大模型固有的局限性
- LLM 的知识不是实时的
- LLM 可能不知道你私有的领域/知识
检索增强生成
RAG(Retrieval Augmented Generation) 顾名思义,通过检索的方法来增强生成模型的能力。
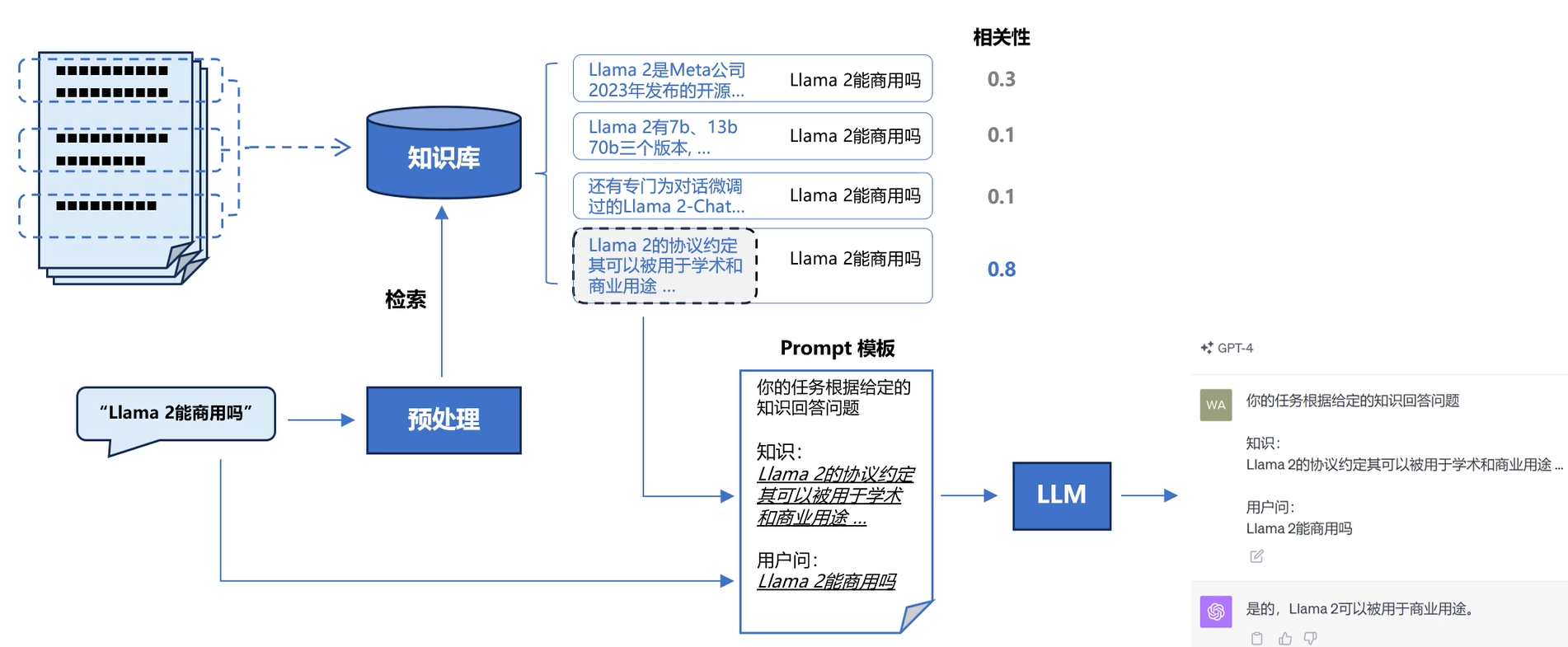
RAG 系统的基本搭建流程
搭建过程:
- 文档加载,并按一定条件切割成片段
- 将切割的文本片段灌入检索引擎
- 封装检索接口
- 构建调用流程:Query => 检索 => Prompt => LLM => 回复
文档的加载与切割
python
pip install --upgrade openai
pip install pdfminer.sixpip install --upgrade openai
pip install pdfminer.six向量检索
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为(x,y),表示从远点(0,0)到点(x,y)的有向线段。

以此类推,我可以用一组坐标(x0,x1,...,xn-1)表示一个 N 维空间中的向量,N 叫向量的维度
文本向量(Text Embeddings)
- 将文本转成一组 N 维浮点数,即文本向量又叫 Embeddings
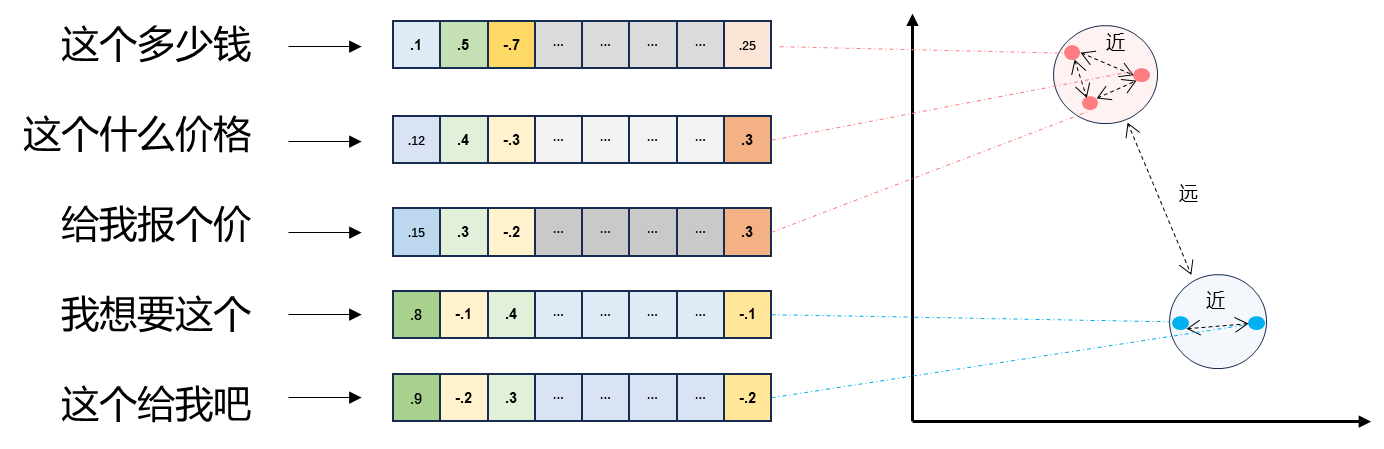
- 向量之间可以计算距离,距离远近对应语义相似度大小
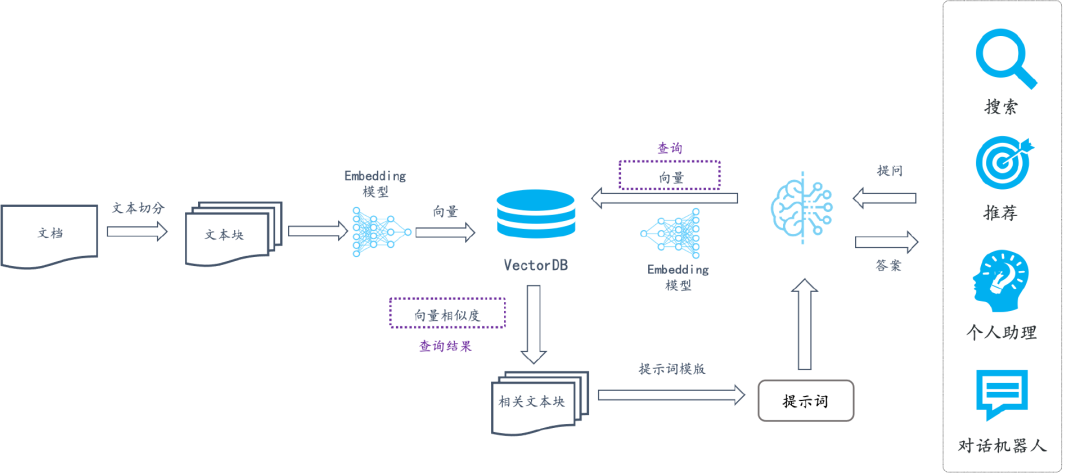
文本向量是怎么得到的
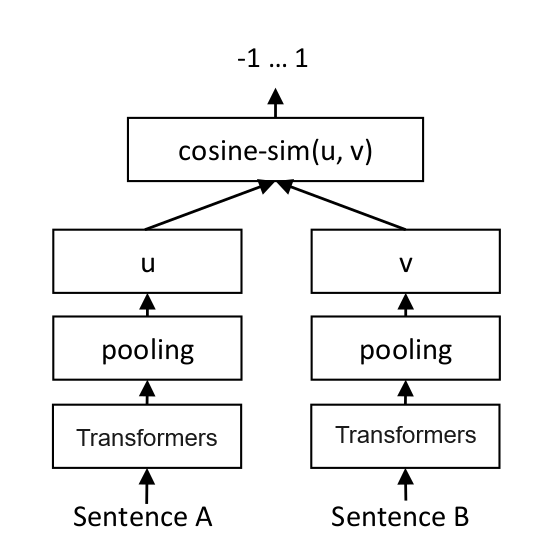
- 构建相关(正例)与不相关(负例)的句子对样本
- 训练双塔式模型,让正例间的距离小,负例间的距离大
例如:
向量间的相似度计算
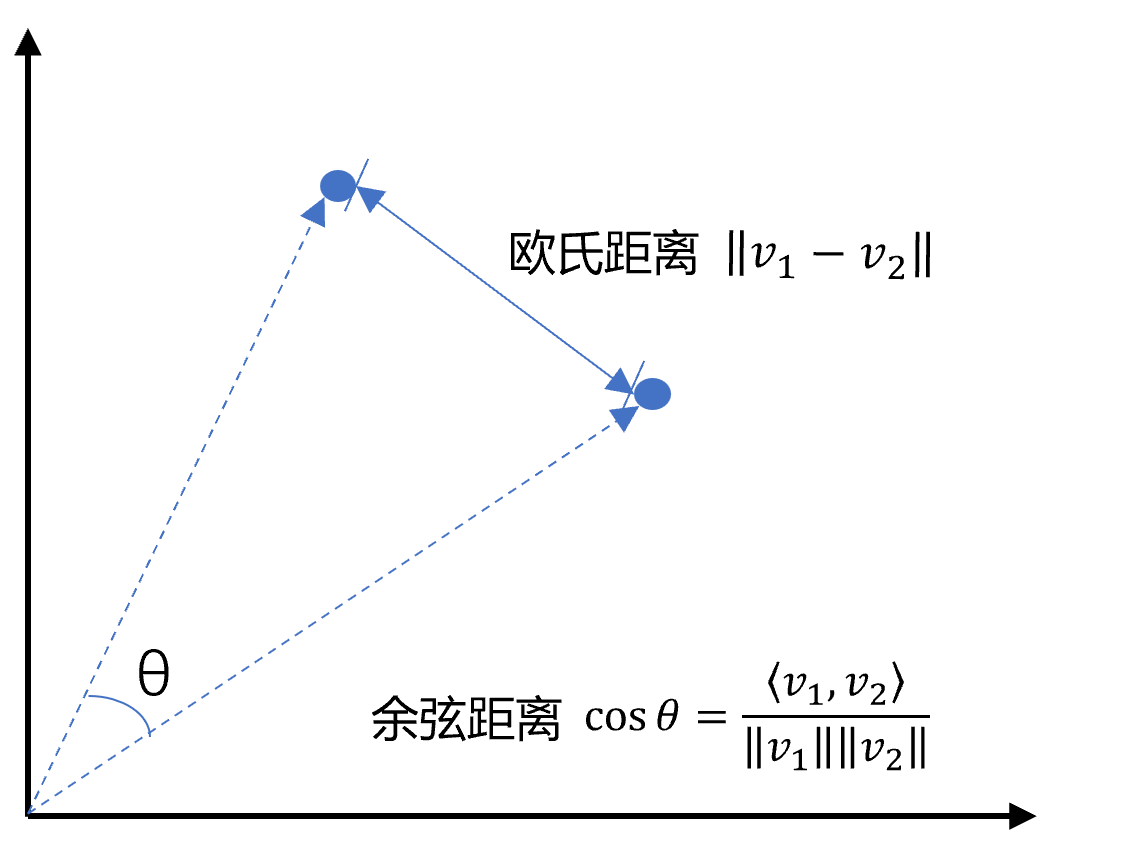
向量数据库
向量数据库,是专门为向量检索设计的中间件
python
pip install chromadbpip install chromadb