
概述
从 ChatGPT 发布以来,当前社会进入到了人工智能时代,大家都知道生产力的进步都表示某种基础设施的建立。
例如:
- 工业时代,电力成为基础设施
- 信息化时代,网络成为基础设施
- 智能时代,大模型成为基础设施
AI/LLM 的分类
- 基础研究:基础研究努力让模型更聪明,涵盖模型核心算法、架构、基础理论、性能优化等,这需要专业的领域知识。
- 应用研究:或称为 LLM 应用开发,是指如何将 AI 应用到实际的业务场景中,让 AI 技术落地,这块就是我们普通程序员的机会。
LLM 在软件开发中的单点提效
作为 LLM 领域最热门的应用——聊天机器人,单纯用聊天方式 LLM 已经能为软件开发提升不少效率了,例如:
- 智能代码提示:能根据对应的注释生成对应的代码。
- SQL 语句智能生成:将自然语言转换成结构化的 SQL 语句。
- 静态代码检查与自动修复:查看程序错误并给出解决方案。
- 单元/接口测试代码生成:根据对应的代码生成单元测试代码。
- 代码评审和重构:审核对应代码的功能。
- 失败用例自动分析与归因:根据程序抛出的错误进行总结分析。
- 重复代码检查:自动检查代码中可复用的部分。
- 跨端代码快速转换:快速将同一个功能的代码转换成另外一种代码,例如 Vue.js 转 React。
- 代码注释生成:快速为每一行代码添加上注释。
- 更精准的技术问答:代替 Google 实现更高效率、更精确的问答。
未来的软件架构思考
在过去几个月里,有大量的 KOL 都在说:所有的应用都值得用 AI 重写一遍,而落地到现有的 DevOps 工具里,假设都需要重写,那么未来的架构可能是什么样的?
基于当前应用的发展,绘制了一份这样的架构图,涵盖了专用硬件、云平台、大模型、 端到端的应用,架构图如下
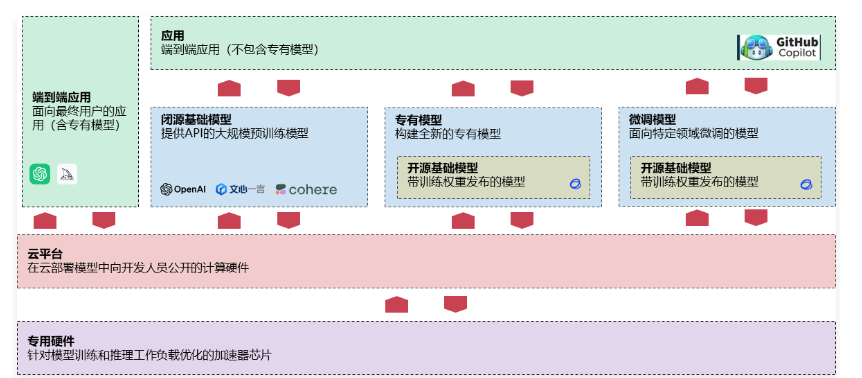
简单解释下各个模块的作用:
- 专用硬件:针对模型训练和推理工作负载优化的加速性芯片,例如:英伟达的 GPU、Google 的 TPU。
- 云平台:基于专用硬件搭建的云平台,在云平台提供了大模型训练、推理用到的相关配套设施,涵盖软硬件,例如:Azure、亚马逊云、阿里云、腾讯云等。
- 大模型:
- 闭源基础模型:提供 API 的大规模预训练模型,例如:OpenAI、文心一言、Cohere、月之暗面等。
- 专有模型:企业构建的全新专有模型+修改训练权重发布的开源模型。
- 微调模型:面向特定领域的微调模型+带训练权重发布的模型。 4.应用:
- 端到端应用:用户可以直接和大模型进行对话的应用,例如:ChatGPT、Midjourney 等。
- 应用:将大语言模型与当前应用进行结合的应用,例如:Github Copilot 等。
转换成对应的能力其实就是 3 种:
- 使用 LLM 的能力(Prompt 工程师):学习 Prompt 编写技巧,提升 LLM 的使用技巧。
- LLM 应用开发的能力(AI 应用开发工程师):将 LLM 功能与当前的应用功能进行结合,学习 LLM 应用开发能力。
- 构建 LLM 的能力(LLM 算法工程师):学习 LLM 的调参、预训练、微调,让 LLM 的能力更强。
AI 编程对程序员的影响
在正式聊 AI 编程对程序员的影响前,我们先来看下按照特定规则划分的 AI 自动化编程的 5 个等级:
- C1:基于当前代码自动补全。
- C2:编写代码时 AI 可以预测下一行代码。
- C3:基于自然语言生成代码与编程语言的翻译。
- C4:高度自动化编程包括自然语言生成代码及注释、自动化测试、编程语言互译、代码补全与生成、调试及检查。
- C5:完全自动编程,AI 可以看成是一个任意的软件,甚至无需代码,基于 AI 本身即可提供对应的服务。
如果按照这 5 个等级,目前大语言模型位于 C3-C4 的阶段,对于一些简单的项目可以一次性完成,复杂项目仍然无能为力。
结合来看,短期内对程序员的影响是比较小+主要以提升效率的方向为主:
- AI 可以帮助程序员完成代码的自动化测试、代码审查等重复、容易出错的工作,但是自动化测试、代码审查只是程序员的一小部分工作,程序员还需要负责沟通、需求拆分、代码维护、版本迭代等功能。
- 在创造性问题上,例如在项目的需求分析、设计和策划过程中,需要程序员进行创造性思考和判断,AI 技术还没有完全达到这一点。
- 对于目前的 AI 进展来说,并不会导致程序员的完全失业,而是在一定程度上提高了程序员工作的效率和准确性。
如果未来真的发展到 C5 这个自动化编程的级别,甚至完全 C4 级别,来聊一聊对程序员的影响:
- 不久的将来 AI 有望取代一些低水平(比如仅会 CURD)的程序员,但是以目前的进展来说,还有一段路需要走。
- 长远的未来,人人都具备编程能力,但是程序员不太应该被单独拿出来讨论,AI 不仅仅对编程产生大量的影响,对各行各业都会形成冲击,例如:律师、医生、教育、机器人、服务业、作家,并且实际上对大模型来说,编程仍然是最具挑战的任务之一,相比生成一张图片、一段文字,代码需要的逻辑性更强。
- 编程还是值得推荐学习的技能,毕竟编程是距离 AI 最近的领域。
AI 编码助手
名词解释
LLM-大型语言模型
LLM 是基于深度学习技术构建的人工智能模型,由具有数以亿计参数的人工神经网络组成,通过自监督学习或半监督学习在大量无标签文本上上进行训练。
LLM 于 2018 年左右出现,并在各种任务上表现出色,LLM 改变了自然语言处理研究的重点,使其不再是以训练特定任务的专门监督模型为范式。ChatGPT、文心一言、Kimi 等都是基于 LLM 开发的聊天机器人应用。
AIGC-AI 生成内容
AIGC(AI-Generated Content)通过对已有数据进行学习和模式识别,以适当的泛化能力生成相关内容的技术。
AIGC 生成的内容很多,涵盖文字、图像、视频、音频、游戏、虚拟人等等。
AIGC 是 AI 大模型,而 ChatGPT 则是 AIGC 在聊天对话场景的一个具体应用。
AGI-人工通用智能
AGI(Artificial General Intelligence)全称人工通用智能,是指能够理解、学习和应用广泛的知识和技能的人工智能系统。
以人类角度来看,AGI 就是一种能够“思考”和“理解”各种问题的智能生命体,就像人类一样。
Agent-智能代理/智能体
Agent(智能代理)一个能够自主感知环境并采取行动的计算实体,其目标是最大化某种预定义的效用或实现特定的目标。
AGI 可以看成是一种非常高级的 Agent,具备广泛适应性和自我学习能力,Agent 也是现阶段 AGI 的最佳实现方式。
Prompt-提示词
Prompt 是指给定的一段文本或问题,用于引导和启发人工智能模型生成相关的回答或内容。
Prompt 是目前人类与 LLM 大语言模型交互的核心方式。需要注意的是,Prompt 本身并不包含问题的答案或具体的内容,它只是一种指导模型生成文本的方式。模型的输出仍然是基于其训练数据和学习到的模式进行生成的。
GPT-生成型预训练变换模型
GPT(Generative Pre-trained Transformer)是一种基于深度学习的大型语言模型。GPT 使用 Transformer 模型架构,它由多个编码器-解码器堆叠而成,通过自注意力机制来处理输入序列和生成输出。模型的训练采用了无监督学习的方法,使用大量的文本数据进行预训练,使模型具备了广泛的语言理解和生成能力。
GPT 模型最初由 OpenAI 开发,旨在通过训练模型预测下一个单词或字符来学习自然语言的统计规律。
Token-文本基础单元
Token 是指在自然语言处理和文本处理任务中,将文本分解成较小单元的基本单位。这些单元可以是单词、字符、子词或其他语言单位,具体取决于任务和处理方式。
大语言模型中的上下文长度计算一般都是基于 Token,而不是字符,例如 GPT-4 的 16K 上下文意味着传递的消息不能超过 16K 个 Token,一般 1 个 Token 等同于 1 个单词,1.5 个 Token 等同于 1 个汉字。
LoRA-插件式微调
LoRA(Low-Rank Adaptation of LLM,低秩)即插件式微调,用于对大语言模型进行个性化的特定任务的定制。
LoRA 通过将模型的权重矩阵分解成低秩的相似矩阵,降低了参数空间的复杂性,从而减少微调的计算成本和模型存储要求。
传统的微调方法通常需要在整个模型上进行参数优化,这可能会导致训练时间长、计算资源消耗大,并且需要大量的标注数据。而低秩适应方法则提供了一种更高效的微调策略,基于对原始模型的分析,选择性地微调模型的某些部分,使其更适应于特定的任务或数据。
矢量/向量数据库
矢量数据库是一种用于存储矢量/向量数据的数据库。
矢量数据库可以存储和管理大量的矢量数据,例如图像、视频、音频、文本等,同时提供高效检索功能。矢量数据库通常基于矢量搜索引擎实现,它可以将矢量数据转换为向量表示,并将其存储在数据库中。在查询时,矢量搜索引擎可以将查询数据转换为向量表示,并在数据库中进行相似度匹配,从而找到与之最相似的数据。
数据蒸馏
数据蒸馏指将给定的原始大数据集浓缩并生成一个小型数据,使得在小数据集上训练出来的模型与原数据集上训练的模型相似。
数据蒸馏在深度学习领域被广泛应用,可以帮助将复杂的模型转换成更轻量级的模型,提高模型的鲁棒性和泛化能力。