
大模型语言
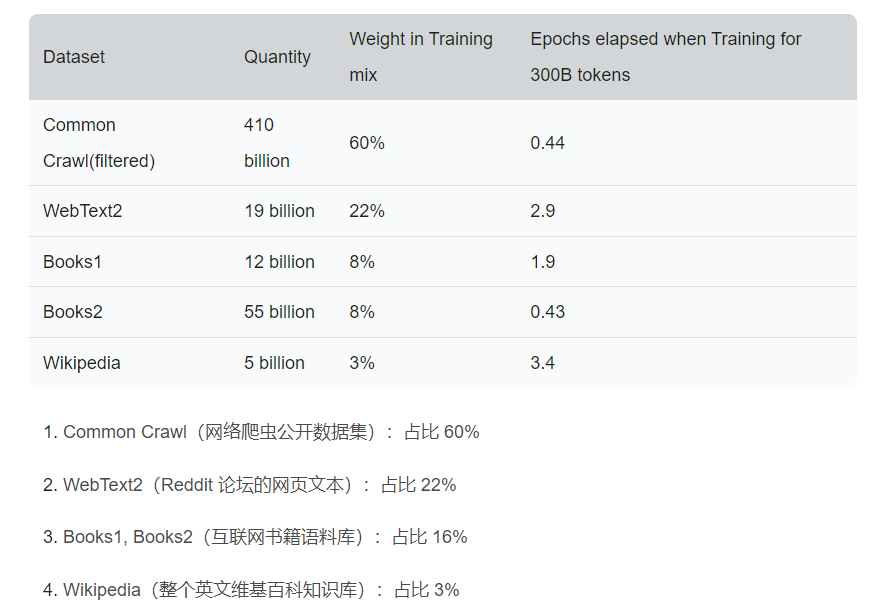
LLM 全称 Large Language Model,即大语言模型,是一种用大量数据训练的深度学习模型,给模型一些输入,它可以预测并返回相应的数据。 和以往的 NLP 自然语言模型有差异的是,LLM 的训练数据和参数量都非常大,所以 LLM 能完成通用型的任务,不需要专门针对某个领域单独训练。 以 GPT-3 为例,GPT-3 的训练数据由多个部分组成,涵盖了书籍、新闻、论文、维基百科、社交媒体等几乎人类所有的高质量文本近 3000 亿个文本单位,分布如下:
除了训练数据大,大模型的参数也非常大,以 OpenAI 历代公开大模型参数量为例。
GPT-1 的参数为 1.17 亿,虽然参数看起来不大,但是对比 GPT-1 之前的语言模型仍增长了数十倍。而 GPT-2 的参数量为 15 亿,GPT-3 的参数量为 1750 亿,未开源的 GPT-4 参数预估量更是达到了惊人的上万亿。
在大训练数据量+大参数的基础下,大模型能够流畅地完成通用型的任务,而不是像 NLP 自然语言模型一样,针对某个特定领域时需要单独的数据训练才可以实现。
- 生成任务:基于特定的输入(例如关键词、短语或描述性的语句)生成全新的内容或想法。这可能包括写作(例如,文章、短篇故事或诗歌)、艺术品生成、音乐创作等。
- 分类任务:涉及确定给定输入属于哪个类别或群组。大语言模型可以从输入信息中抽取特征,并将其分类到适当的类别。包括情感分析(把文本分为积极,消极,或中性)、图像分类(识别图像中的对象或景色)、语言识别(识别特定的语言类型或方言)等。
- 总结任务:从大量的信息中抽取关键点并生成一个简洁的总结。包括文章摘要(把长篇文章精简为几句关键信息)、会议记录总结(将长时间的会议记录转化为主要讨论点)等。大语言模型能够理解和提炼信息,提供简明、准确的总结。
- 改写任务:指将信息或内容在保持原意的情况下重新表述。包括文本改写(例如,将复杂的语句转化为易懂的语言)、语义等价句生成(例如,用一种新方式表达同一思想)、语言翻译等。大语言模型能够理解语义,从而在改写时保持原始信息的准确性与合理性。
那目前为止,什么样的参数量才能被称为大呢?一般来说参数量大指的是 7b~100b+(b 指的是 billion,单位为十亿),也就是 70 亿~1000 亿 参数量。
简单来说,参数其实就是一个浮点数,例如 3.1415,而在计算机内,使用 2 字节或者 4 字节来存储浮点数类型的数据,70 亿个参数的大小也仅仅为 28G。
那么一坨 28G 的数据为什么能和我们进行流畅对话呢?
大语言模型中的 Token、词表与预测
在大语言模型中,计算长度的依据并不是字符,而是 Token,Token 其实就是文本片段,可以是字、词、甚至是半个字或者三分之一个字。
比如 GPT-3.5-16K 模型的上下文长度是 16K,意思就是单次对话的最多可以包含 16,000 个 Token(文本片段)。
不同模型的 Token 是不一样的, 对于一个仅支持英语的模型,它的 Token 可能非常少,仅包含 a-z 26 个字母、逗号、句号、空格等标点符号。
而汉字字词更多,语义会更复杂,所以包含的 Token 会更多,在一些支持多语言的模型中,Token 会包含各种符号、单词、单词片段等,所以往往会有几十万个 Token 甚至更多(GPT 模型的 Token 数更是达到了 30+ 亿,所以大模型会有各种可能的输出)。
将 Token 按顺序排列组成的表叫词表,在词表中每个 Token 都有其对应的 id,一般从 0 开始,如下
"vocab": {
# 开头是一些特殊符号
"<unk>": 0,
"<|startoftext|>": 1,
"<|endoftext|>": 2,
"<|Human|>": 3,
"<|Assistant|>": 4,
...
# 这是字节token,如果出现不在词表中的特殊符号会回退到字节表示
"<0x00>": 305,
"<0x01>": 306,
"<0x02>": 307,
"<0x03>": 308,
"<0x04>": 309,
...
# 下面是正常的英文token,有_的表示是单词的开头,没有的是单词中间
"ct": 611,
"▁re": 612,
"ve": 613,
"am": 614,
"▁e": 615,
...
# 有中文token出现
"安徽省": 28560,
"▁aliens": 28561,
"▁imagery": 28562,
"▁squeeze": 28563,
"子和": 28564,
...
}"vocab": {
# 开头是一些特殊符号
"<unk>": 0,
"<|startoftext|>": 1,
"<|endoftext|>": 2,
"<|Human|>": 3,
"<|Assistant|>": 4,
...
# 这是字节token,如果出现不在词表中的特殊符号会回退到字节表示
"<0x00>": 305,
"<0x01>": 306,
"<0x02>": 307,
"<0x03>": 308,
"<0x04>": 309,
...
# 下面是正常的英文token,有_的表示是单词的开头,没有的是单词中间
"ct": 611,
"▁re": 612,
"ve": 613,
"am": 614,
"▁e": 615,
...
# 有中文token出现
"安徽省": 28560,
"▁aliens": 28561,
"▁imagery": 28562,
"▁squeeze": 28563,
"子和": 28564,
...
}有了 Token + 词表,我们就可以来看下大语言模型的工作流程:
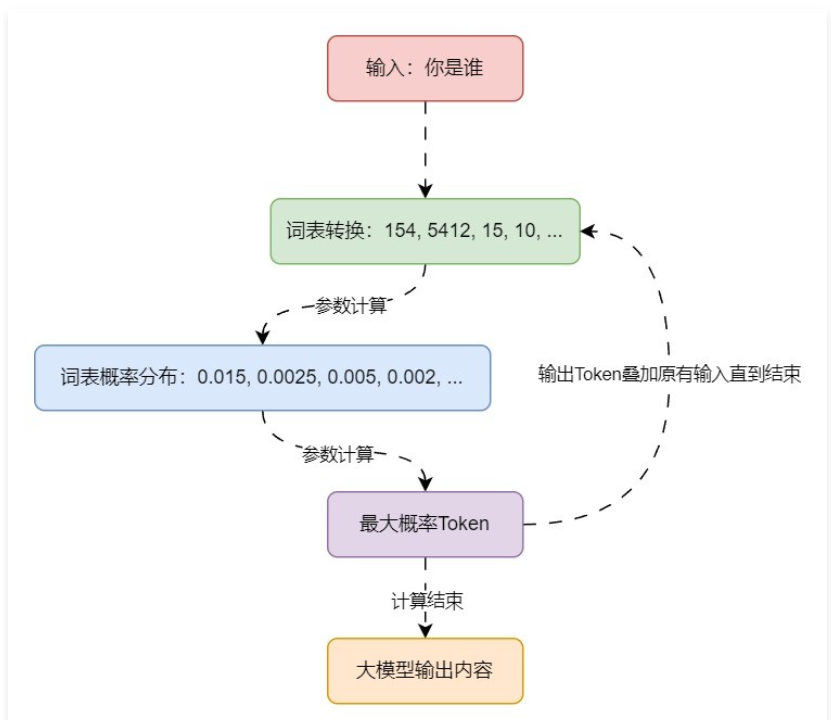
从非机器学习的角度来讲讲大语言模型的 Token 预测机制,一种最简单的办法就是基于统计,通过大量数据的统计,找到下一个 Token。例如:采集大量文本进行扫描计算,并记录所有片段的输入以及下一个文本出现的次数,得到一张巨大的分布表。
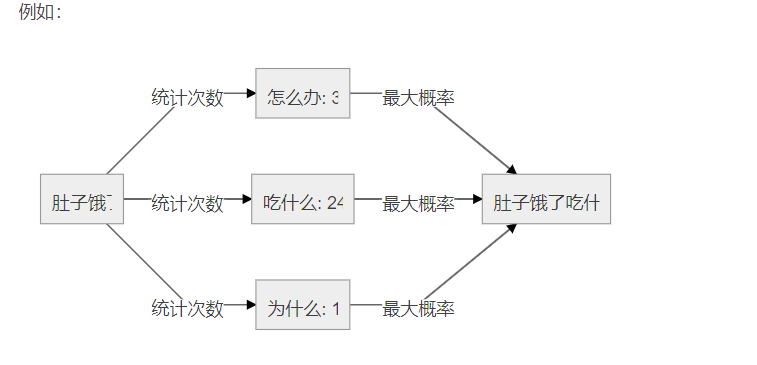
然后将将输入的文本对照分布表查询,找到所有 token 的出现次数或概率,找到出现次数最大的 token 即为预测结果。
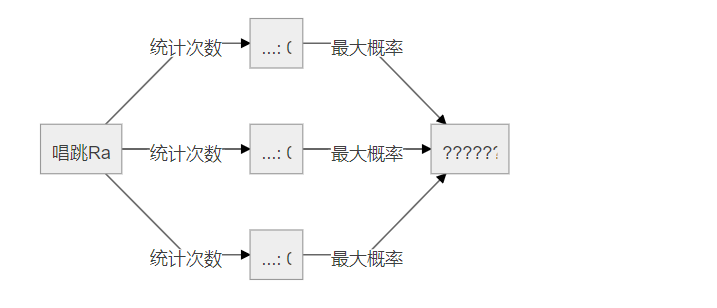
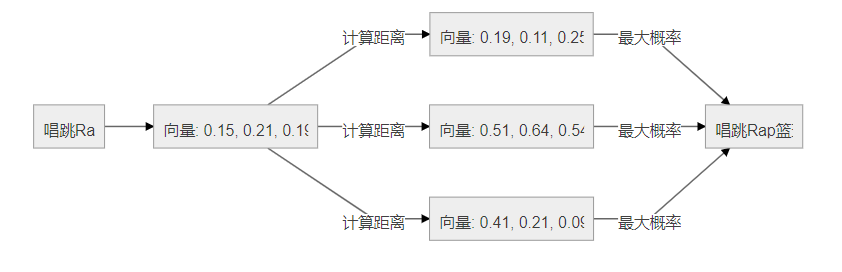
但是基于统计的情况对于没有统计到的片段就无能为力了,比如“唱跳 Rap”这个片段并没有在统计中,基于统计的算法会将所有的 Token 出现次数都设置为 0,如下
这个时候就可以考虑将输入+词全部转换成向量/文本嵌入,通过向量与向量之间的距离越近,看成概率越大来解决这个问题,在实际的模型中,往往会比这个复杂得多 ,添加向量转换后,整个流程图如下
大语言模型中的训练
训练指的是将大量文本输入给模型,进而得到模型参数,目前 LLM 训练一般用到了大量文本,一般在 2T token 以上(2 万亿 Token )。 这里我们以“程序员的梦工厂”这句话作为训练,来看下整个流程,当然这个流程也是极大地简化了。
- 初始化模型的所有参数,所以一开始的时候,70 亿个参数都是随机初始化的,无论输入什么都会输出随机乱码;
- 将“程序员的梦工厂”这句话作为 LLM 的训练预料,并假设每个字都是一个 token;
- 将第一个 token 输入给模型,即输入“程”;
- 经过一系列复杂而昂贵的计算后,模型输出了一个随机的概率粉笔,概率最大的可能是“hello”;
- 正常应该输出“序”,所以错得很离谱,通过计算模型输出和真实的 label 直接的交叉熵 loss,它的输出越接近正确,这个 loss 越小;
- 使用梯度下降的方法来调整整个模型的 70 亿参数,调整过后可以使得下次对于同样输入的情况下,它的输出会“错得少一点”,这样就完成了一个 step 的训练;
- 第 2 个 step 中,我们将输入“程”+“序”两个 token 给模型,并期望模型输出“员”这个 token,根据模型的输出和“员”的差异,确定 loss 的大小并通过反向传播来调整模型参数。
- 以此类推。
一次经过简化版的训练流程如下

如此重复万亿次,一个大语言模型的训练就完成了,前面讲过,目前 LLM 一般的训练数据量在 2T token 左右,于是这个过程就是重复 2 万亿次。70 亿参数的一次计算其实计算量已经非常大了,再乘上 2 万亿。这也就是大模型一次训练的成本都在成百上千万的原因
LLM 在企业中的价值与市场需求
从目前 AI 应用的落地来看,主要包含提升效率、创造增长、决策赋能。
在大模型出现之前,AI 人工智能已经已经在各行各业中了,有以决策为特长的老一代机器学习应用,也有侧重感知能力的“传统”深度学习应用,例如:谷歌/百度/腾讯等大厂的翻译网站、已广泛应用到高铁进出站的“人脸识别”都是深度学习的典型用例。
2023 年 GPT-4 发布后,张勇在阿里云峰会上宣布阿里所有产品未来都将迎来升级,并且强调 AI 大模型的出现是一个划时代的里程碑,人类将进入到一个全新的智能化时代,所有的产品都值得用 AI 重做一遍。
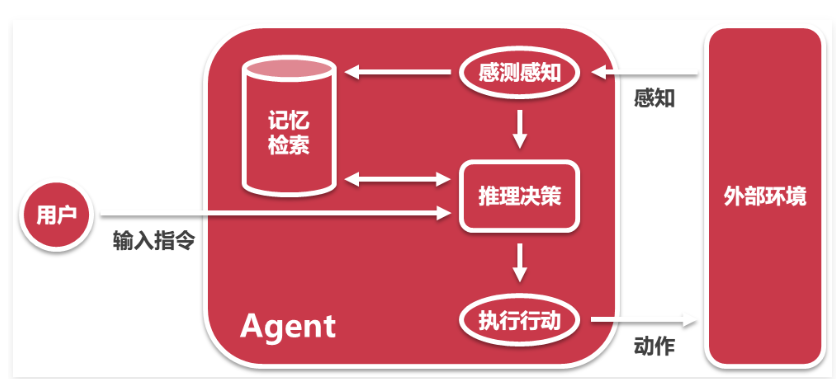
通用人工智能(AGI)将是 AI 的终极形态,几乎已成为业界共识。类比下来,构建智能体(Agent)则是 AI 工程应用当下的“终极形态”。 智能体指代具有自主性和智能的程序或系统,能够通过感知、规划、决策并执行相关任务。以下是智能体的一个简单架构图:
LLM(Large Language Model)作为 AI 工程的最重要代表之一,从 ChatGPT 发布至今,为企业带来了哪些价值呢?简单给大家整理了 3 个应用场景案例,从这小小的冰山一角来看看 LLM 带来的变化。
1.重塑企业智能客服
企业的传统客服存在效率低、人员培养成本高、工作压力大、提供的服务参差不齐等问题。在线客服是企业与客户沟通的一个重要桥梁,可以为企业带来更多的商机,而 LLM 最广泛的落地应用就是——AI 智能客服。
利用 LLM + 企业自有知识库构建的 AI 智能客服机器人,对比传统客服,可避免诸多问题的产生:
- 智能沟通:媲美真人的声音、智能引导问答,在企业自有知识库的投喂下,对答如流;
- 无间断工作:7 × 24 小时不间断工作,为客户提供自助服务;
- 智能分析:全程监控机器人对话,分析用户问题,并进行分类,方便后期的管理及维护;
- 自动分类:为用户创建画像建模,准确分析归类用户,方便提供个性化服务;
- 成本管控:减少人工坐席,降低员工流动损失和各种人力成本,而且随着算力的发展,使用 LLM 的成本会越来越低;
- 跨语言:可以将不同语言和平台的客户需求整合起来,提供前面的解决方案;
2.企业数据分析和洞察
几乎所有企业每天都会产生大量的数据,并且除了新产生的数据外,还有海量的历史沉淀数据,这部分历史沉淀数据类型多,涉及到各式各样,例如:日志、历史代码、订单、会员信息、行业数据等等,并且数据量庞大,各个架构也有差异。而对这类数据,企业的利用率非常低,这导致了企业很难精确获知和建立各项数据之间的关联。
利用 Agent/LLM 参与数据的自动分类、信息提取、数据分析等,建立起各项数据之间的关联。
在我所在的企业内部,我们将新老职员需要交接的数据录入数据库,使用 LLM 读取数据库的内容来实现“交接机器人”功能,从过新职员的提问+引导,实现快速交接。
3.人工智能即服务(AIaaS)
这是一个非常新颖的改变,并且正在改变现代企业的布局,万物均可 AI。让公司发布一款产品变得异常简单,无需投入昂贵的硬件、专业人才或耗时的开发流程,这就像按需租用一个人工智能发电站,可以根据业务需求进行定制和扩展。
一些常见的案例如下:
百度翻译:后端使用神经网络模型来实现将一种语言翻译成另一种语言,需要单独采集数据、训练、部署、开发 API。而在 AIaaS 中,通过限定的预设 Prompt + 规范化输出,企业一分钟就能实现一个翻译 API,而无需了解翻译模型的具体实现细节、数据采集、训练和部署等复杂过程。用户只需按照提供的 API 规范进行调用,即可快速实现翻译功能,节省了大量的人力物力成本。
自动化运维:通过采集后端的日志,利用 LLM 进行推理决策并调用相应的运维工具,实现运维的自动化、24h 自动化运维,节省了大量的人力物力成本。
AI 爆火下的市场需求
简单聊完 LLM 为企业带来的价值,那么 LLM 能为作为开发者的我们带来什么价值呢?首先明确一点,人工智能大潮已来,不加入就淘汰,就好比现在职场谁不会用 PPT 和 Excel,在现阶段,AI 几乎不会淘汰任何岗位,但是会大大减少某些岗位的需求,并且创建出大量新的岗位,例如:大语言模型训练工程、大语言模型应用工程师、Prompt 提示词工程师、对话设计师等。
在 AI 的加持下,出现了大量与大模型相关的岗位,例如:AI 应用工程师、大模型研发工程师等,对比 Java、前端等行业内卷不那么严重,并且行业前景更好。
学习 LLM 相关知识对职业发展的潜在影响
人工智能浪潮已来,不加入就淘汰的说法虽然很夸张,但是 AI Agent/LLM 会像过去的 PPT 和 Excel 一样,成为几乎所有职业必学的技能,这一点从 ChatGPT 成为用户增长最快的产品就可以看出(2 个月时间从 0 增长到 1 亿用户数,比 TikTok 还快 7 个月)
LLM&AI Agent 应用的交互模式
传统人机交互范式
传统的人机交互范式是以人作为主导,人从外部环境获取数据(结构或非结构的数据),将数据传递给软件进行交互,随后接收软件产生的结构或非结构的数据,整体的架构流程如下
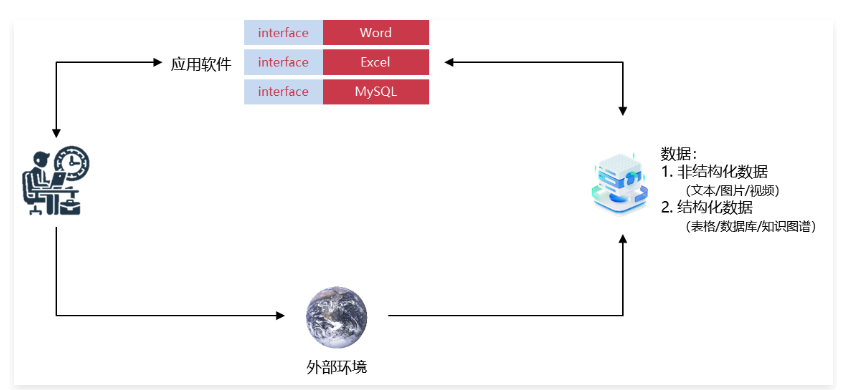
在这种传统交互范式下,缺点也非常明显:
- 交互接口复杂繁杂且多样化,要使用多一款软件,要专门花时间去学习,每个软件之间接口差异巨大。
- 人在环境中进行一些行为,会产生各类的数据,涵盖结构化和非结构化数据,而人不能和数据直接发生关系,需要一个中介,这个中介就是软件。
- 处理不同的数据需要不同的软件,而有些软件非专业人士很难上手,比如说 PhotoShop。
大模型时代的人机交互
在大模型时代,引入了 LLM,交互的中心就变成了 LLM,新的交互范式如下
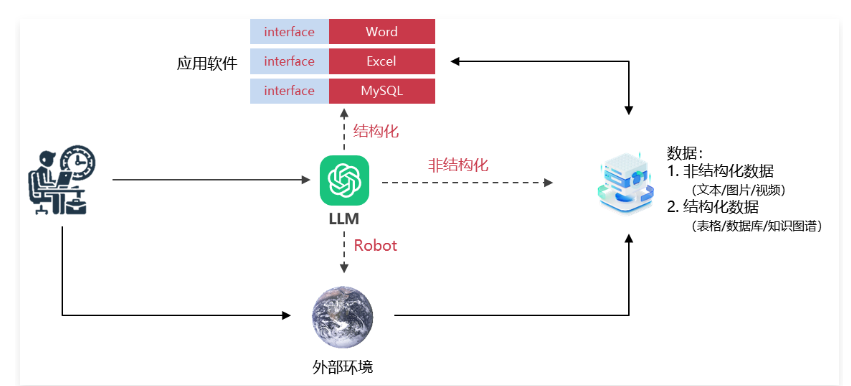
新交互范式下,引入了 LLM,人直接通过与 LLM 进行交互,LLM 会获取外部环境数据,并将用户与外部环境整理得到的数据传递给应用软件进行交互,最后将结果反馈给人类。
新交互范式特点也非常明显:
- 过去通过某个应用软件与某种数据进行交互,现在变成人和大模型交互,即大语言模型站到了人机交互的中心位置。
- 本质上还是人和数据的关系,只是由于大模型的出现,应用软件被屏蔽到了幕后。
- 短期来看,LLM 可以代替一些应用软件,比如多模态大模型对 PhotoShop 的取代;长期来看,大模型可能会逐步替代各种功能的软件。
如果未来 LLM 足够强大,甚至软件这一部分都不需要了,将 LLM 视为一个万能的软件,所有软件的功能 LLM 都可以单独完成,当然这个目标太远了。
那么在新交互范式背后发生了什么呢?
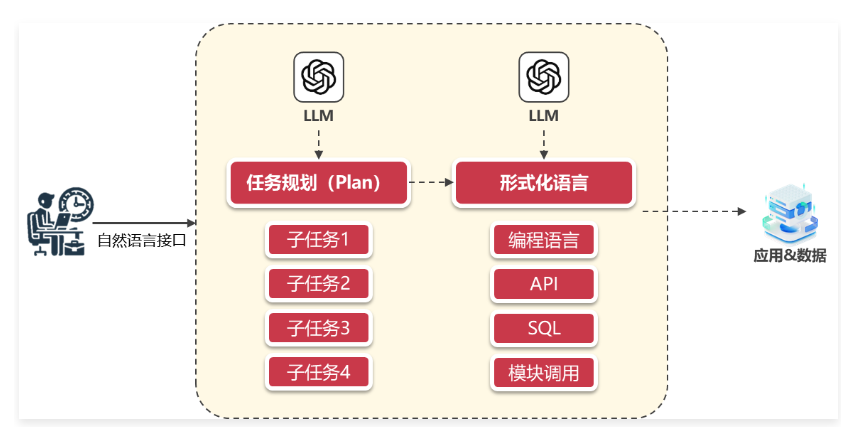
原本人类需要通过多个软件或者多次与外部环境交互才能得到对应的数据,有了 LLM 后,通过强大的自然语言理解能力,LLM 可以将人类的需求/操作拆分成对应的任务规划,并转换成对应的形式化语言,调用外部工具来实现整个复杂的需求。
按照这种新交互范式的软件类型,可以将对应的软件划分为 3 种主流模式:
- 嵌入(Embedding)模式:用户通过与 AI 交流,AI 协助完成,如创作小说、音乐、3D 内容等,此模式下,AI 是执行工具,人类是决策者和指挥者。
- 副驾驶(Copilot)模式:在这种模式下,人类与 AI 作为合作伙伴,共同完成任务,AI 提供建议并协助任务,二者互补,AI 更像知识丰富的伙伴而非工具。
- 智能体(Agent)模式:人类设定目标并提供资源,AI 独立完成大部分工作,最后人类监督和评估结果。
从 LLM 大模型到 AI Agent 的技术演进
LLM/RAG/Agent 已经成为人工智能领域进步的关键技术,理解这三者的概念与关系是做好面向 AI 编程开发的基础。
这里我绘制了一张表格,用于展示这三者之间的关系
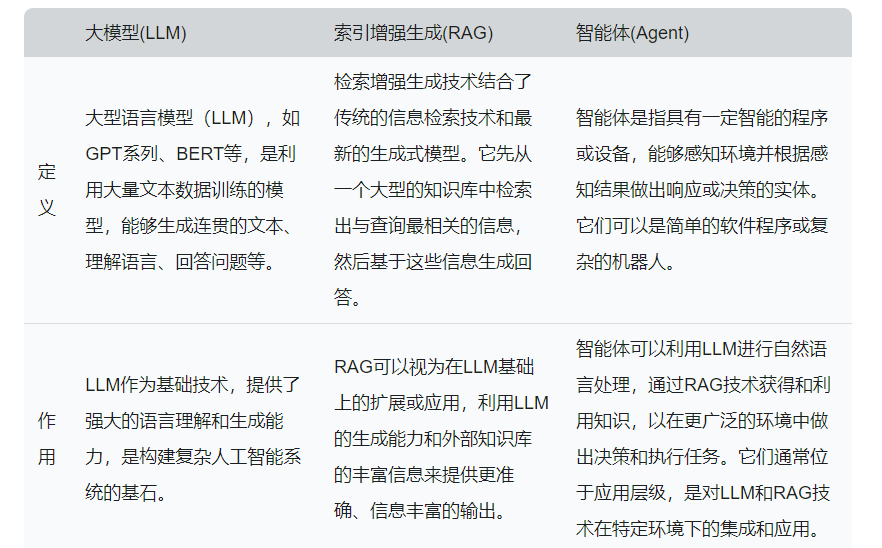
简单来说,LLM 作为最基础的技术,是构建复杂人工智能系统的基石,LLM 的最主要功能就是用户输入特定的信息,LLM 生成对应的内容。
在 LLM 的基础上,利用外部的知识+信息来提供特定的 Prompt,让 LLM 基于提供的内容生成相应的信息,就衍生出了 RAG 的概念,RAG 可以扩展 LLM 的能力,让 LLM 生成更准确的内容。
在 RAG 的基础上,添加对应的工具、Prompt、动作执行者等内容,这样就构成了 Agent(智能体),智能体利用 LLM 进行自然语言处理,通过 RAG 获取外部的知识,通过工具与外部环境进行交互,是对 LLM 和 RAG 技术在特定环境下的集成和应用。
了解完 LLM、RAG、Agent 三者之间的关系,对于 Agent 的定义,其实一直在变化,OpenAI 将 AI Agent 定义为,以大语言模型为大脑驱动,具备自主感知能力、规划、记忆和使用工具的能力,能够自动执行完成复杂任务的系统